
那些年看过的小说都在讲什么?!
—— 用python进行keyword extraction(关键词提取)以及word cloud(词云)绘制
0. Keywords
- Segmentation分词, keyword extraction关键词提取 -
jieba结巴 - display -
wordcloud
1. Segmentation and Keyword Extraction - Jieba结巴
- “Jieba” (Chinese for “to stutter”) Chinese text segmentation: built to be the best Python Chinese word segmentation module.“结巴”中文分词:做最好的 Python 中文分词组件。
- Project site of Jieba
- Fast install:
pip install jieba - Algorithm
- Based on a
prefix dictionary structureto achieve efficient word graph scanning. Build a directed acyclic graph (DAG) for all possible word combinations.基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG) - Use
dynamic programmingto find the most probable combination based on the word frequency.采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合 - For unknown words, a
HMM-based model is used with theViterbialgorithm.对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
- Based on a
1.1 Segmentation
以海子的《祖国(以梦为马)》, or Motherland, or Dream as a Horse in English为例:
#encoding=utf-8
import jieba
sentence = "我要做远方的忠诚的儿子/和物质的短暂情人/和所有以梦为马的诗人一样/我不得不和烈士和小丑走在同一道/路上"
print "Input:", sentence
words = jieba.cut(sentence, cut_all=False)
print "Output 精确模式 Full Mode:"
print(" / ".join(words))
output:
我要 / 做 / 远方 / 的 / 忠诚 / 的 / 儿子 / / / 和 / 物质 / 的 / 短暂 / 情人 / / / 和 / 所有 / 以梦为 / 马 / 的 / 诗人 / 一样 / / / 我 / 不得不 / 和 / 烈士 / 和 / 小丑 / 走 / 在 / 同一 / 道 / / / 路上
1.2 Keyword Extraction
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags_with_weight.py [file name] -k [top k] -w [with weight=1 or 0]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
parser.add_option("-w", dest="withWeight")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
if opt.withWeight is None:
withWeight = False
else:
if int(opt.withWeight) is 1:
withWeight = True
else:
withWeight = False
content = open(file_name, 'rb').read()
#jieba.analyse.set_stop_words("../extra_dict/stop_words.txt")
#jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=withWeight)
with open('extract-tags-with-weight-result.txt','w') as output:
if withWeight is True:
for tag in tags:
#print("tag: %s\t\t weight: %f" % (tag[0],tag[1]))
output.write("tag: %s\t\t weight: %f\n" % (tag[0].encode('utf-8'),tag[1]))
else:
#print(",".join(tags))
output.write(",".join(tags).encode('utf-8'))
output.close()
以张悬的《艳火》歌词进行测试:
Can never get tired of its Chorus——
于是你不停散落 我不停拾获 /我们在遥远的路上 白天黑夜为彼此是艳火 /如果你在前方回头 而我亦回头 /我们就错过
python extract_tags_with_weight.py yanhuo-lyrics.txt -k 20 -w 1
output:
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/6_/zdgf1zs57dd835ctxlbr7k4m0000gn/T/jieba.cache
Loading model cost 0.409 seconds.
Prefix dict has been built succesfully.
tag: 扑火 weight: 0.679005
tag: 相视 weight: 0.546269
tag: 回头 weight: 0.356135
tag: 我们 weight: 0.316946
tag: 拾获 weight: 0.259826
tag: 不停 weight: 0.252306
tag: 是艳火 weight: 0.223454
tag: 遥远 weight: 0.212270
tag: 前方 weight: 0.210153
tag: 快乐 weight: 0.208184
tag: 白天黑夜 weight: 0.194470
tag: 路上 weight: 0.176170
tag: 许诺 weight: 0.165316
tag: 散落 weight: 0.164963
tag: 真的 weight: 0.157955
tag: 错过 weight: 0.155321
tag: 于是 weight: 0.144295
tag: 什么 weight: 0.133342
tag: 彼此 weight: 0.127790
tag: 此刻 weight: 0.125619
2. WordCloud
- A little word cloud generator in Python. Read more about it on the blog post or the website. The code is Python 2, but Python 3 compatible.
- Project site of WordCloud
- Fast install:
pip install wordcloud
3. Examples
3.1 My Python Code
-
Use
MATPLOTLIBandWORDCLOUDto plot figures -
ImageColorGeneratorin WordCloud can generate figures based on specific pictures - Plan in future:
- add own stopwords; and
- use own dictionaries
- ATTENTION! – decode and encode
- Many Chinese files are encoded with GB2312
- However Python recognize characters in UTF-8
CHARDETcan detect coding type of your inputs:detect = chardet.detect(content)
# or !/usr/bin/env python
# or -*- coding: utf-8 -*-
# title: extract_tags_with_weight_v2.py
# by Sian, Nov 14, 2016
import sys
# sys.path.append('../')
from os import path
import jieba
import jieba.analyse
from optparse import OptionParser
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from scipy.misc import imread
# import codecs
import chardet
# obtain current path
# __file__ is current file, report during ide running, could be replaced as
# d = path.dirname('.')
d = path.dirname(__file__)
USAGE = "usage: python extract_tags_with_weight_v2.py -i [input] -o [output] -m [mask input] -p [cloud output] -k [top k] -w [with weight=1 or 0]"
parser = OptionParser(USAGE)
parser.add_option("-i", dest="file_name")
parser.add_option("-o", dest="output_name")
parser.add_option("-m", dest="mask_name")
parser.add_option("-p", dest="pic_name")
parser.add_option("-k", dest="topK")
parser.add_option("-w", dest="withWeight")
opt, args = parser.parse_args()
if opt.file_name is None:
print(USAGE)
sys.exit(1)
file_name = opt.file_name
output_name = opt.output_name
mask_name = opt.mask_name
pic_name = opt.pic_name
print ('\n\t[INTPUT] = %s\t [OUTPUT] = %s\n' % (file_name, output_name))
print ('\t[IMAGE MASK] = %s\t [CLOUD PIC] = %s\n' % (mask_name, pic_name))
print ('\t[KEYWORDS COUNT] = %f\t [WITH WEIGHT (1 OR 0)] = %f\n' % (int(opt.topK), int(opt.withWeight)))
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
if opt.withWeight is None:
withWeight = False
else:
if int(opt.withWeight) is 1:
withWeight = True
else:
withWeight = False
content = open(file_name, 'rb').read()
detect = chardet.detect(content)
print ('\t[CHAR TYPE DETECTION] = %s\n' % detect['encoding'])
# stop words
#jieba.analyse.set_stop_words("../extra_dict/stop_words.txt")
# user dict
#jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=withWeight)
# write to output file
sum_weight = 0
with open(output_name,'w') as output:
if withWeight is True:
for tag in tags:
#print("tag: %s\t\t weight: %f" % (tag[0],tag[1]))
output.write("tag: %s\t\t weight: \t%f\n" % (tag[0].encode('utf-8'),tag[1]))
sum_weight=sum_weight+tag[1]
else:
#print(",".join(tags))
output.write(",".join(tags).encode('utf-8'))
output.write("\nsum of weight: %f\n" % sum_weight)
output.close()
# read the mask image
coloring = imread(path.join(d, mask_name))
# wordcloud
image_colors = ImageColorGenerator(coloring)
wordcloud = WordCloud(
font_path = "/Users/hessiatrix/Downloads/simsun.ttc",
background_color = 'white',
mask = coloring,
color_func=image_colors,
max_font_size = 100,
random_state = 42).generate_from_frequencies(tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.figure()
plt.show()
# save pic
wordcloud.to_file(path.join(d, pic_name))
plt.close()
3.2 Example 1: Sword of the Yue Maiden by Jin Yong 金庸《越女剑》
- My fav of Jin Yong!
阿青回过身来,叹了口气,道:“白公公断了两条手臂,再也不肯来跟我玩了。”范蠡道:“你打断了它两条手臂?”阿青点头道:“今天白公公凶得很,一连三次,要扑过来刺死你。”范蠡惊道:“它……它要刺死我?为什么?”阿青摇了摇头,道:“我不知道。”
python extract_tags_with_weight_v2.py -i 越女剑.txt -o yuenvjian.txt -m yuenvjian-1.jpg -p yuenvjian-cloud-1.png -k 2000 -w 1
- Mask image

- WordCloud image
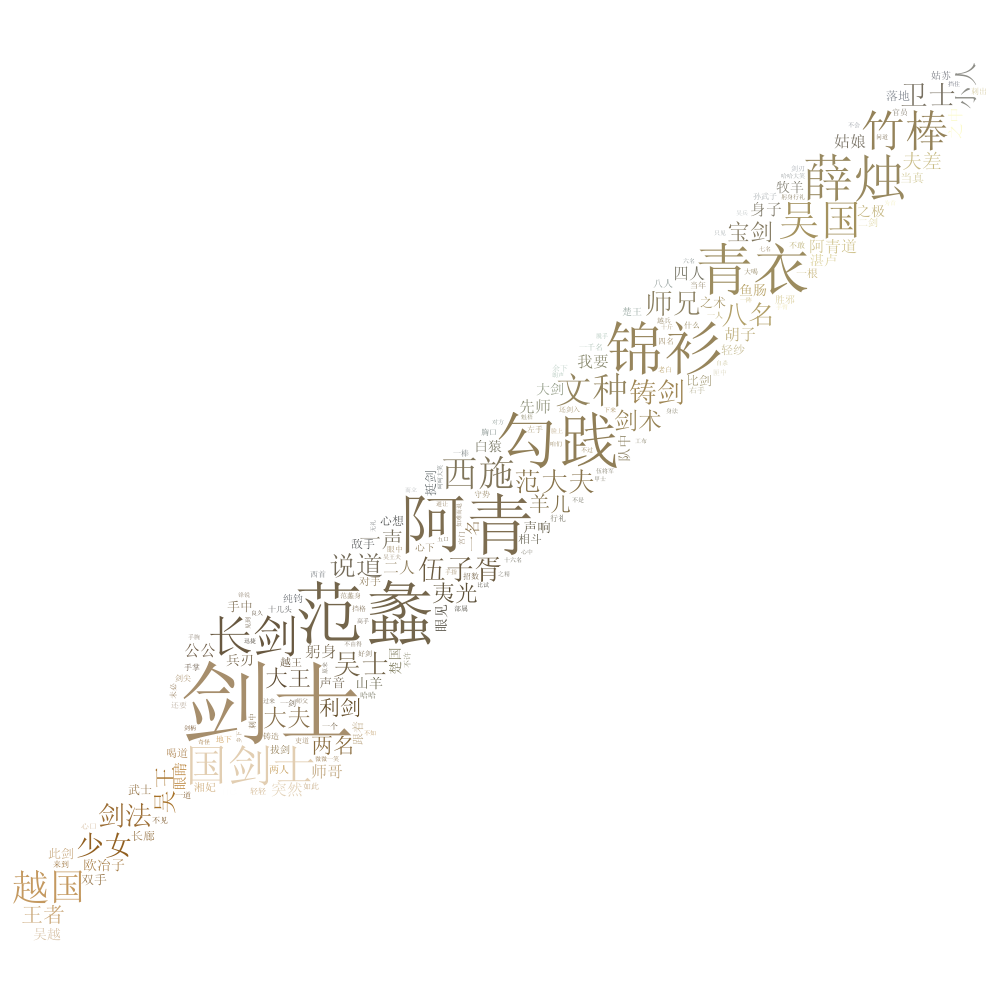
3.3 Example 2: 雪满梁园《鹤唳华亭》
靖宁元年季春的这日,有畅畅惠风,容容流云。天色之温润可爱,一如粉青色的瓷釉。交织纷飞的柳絮和落樱,于白日下泛起莹莹的金粉色光华。在釉药薄处,微露出了灰白色的香灰胎来。 那便是天际了。 她撤回目光,整理罢身上青衫,默默跟随同侪跻身进入了朱红色的深墙。
- Simple WordCloud image

- white background

- black background
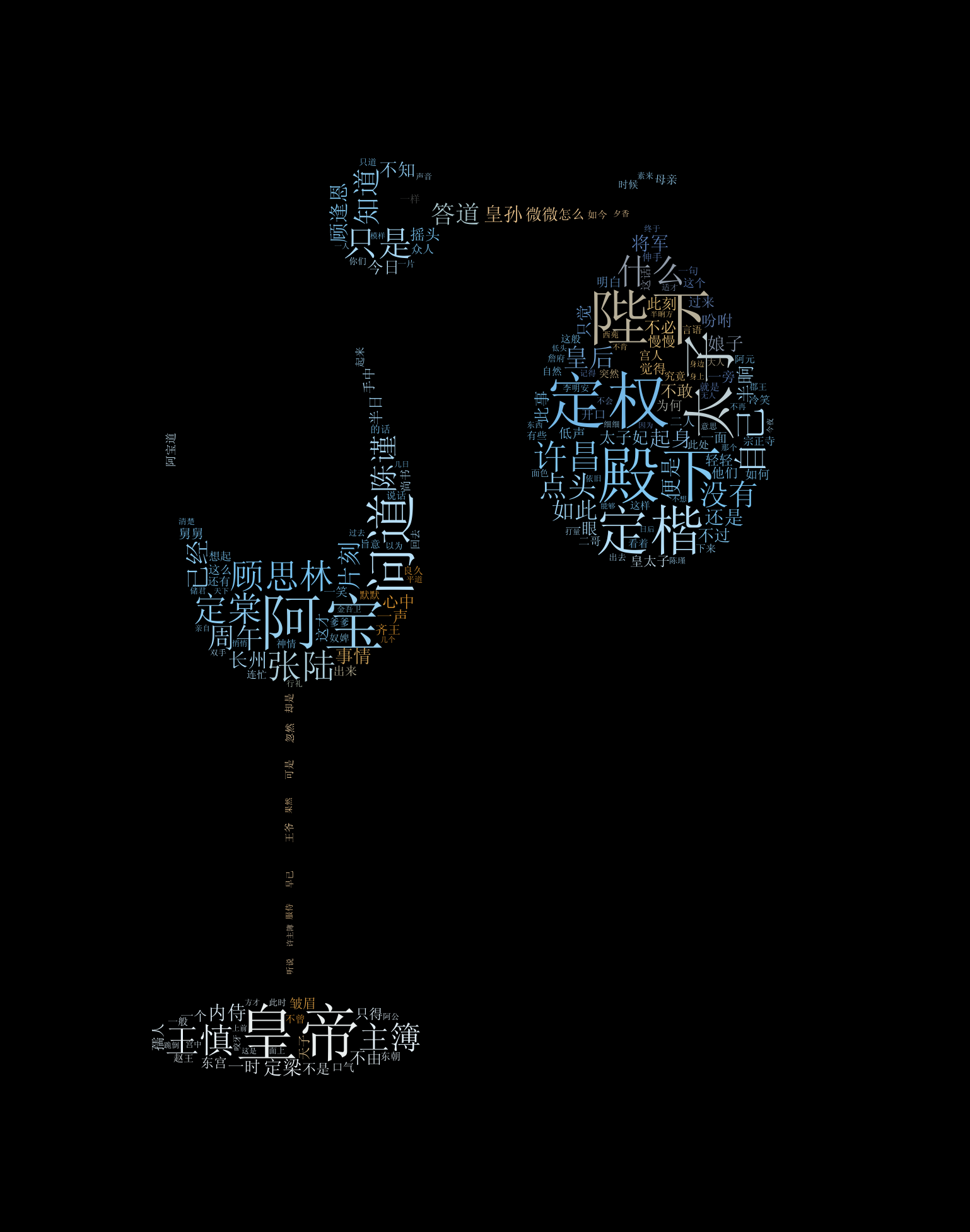
3.4 Example 3: Scarlet Heart, or Startling by Each Step by Tong Hua 桐华《步步惊心》
- 为了找一部更典型的+影视化的晋江小说……
-
There is also a Korean version of this drama: 달의 연인 - 보보경심 려
- Mask image

- WordCloud image

- If you do not pay attention to the coding types…
